These sound-studies highlights of the week originally appeared in the January 30, 2024, issue of the Disquiet.com weekly email newsletter, This Week in Sound. This Week in Sound is the best way I’ve found to process material I come across. Your support provides resources and encouragement. Most issues are free. A weekly annotated ambient-music mixtape is for paid subscribers. Thanks.
▰ CLONE WARS: “Your group should set up a password for situations where you need to confirm identities over the phone. Let’s say it’s ‘raspberry beret.’ If you get a call from a loved one in trouble, you can say, ‘Look, there are scams, and we talked about this — what’s the password?’ The password should be something familiar that’s easily remembered but not associated with you online. A family joke can be good. You don’t have to be strict about them getting it perfect—you’re not verifying their nuclear launch code authority.” —Glenn Fleishman shares advice for avoiding the trap of voice deepfakes.
▰ FRINGE SCIENCE: Science still has much to learn about how owls fly so silently: “Previous studies have found a link between noiseless flight and the presence of micro-fringes in owl wings. These are referred to as ‘trailing-edge’ (TE) fringes. These appear to be the crucial factor in quiet owl flight. … ‘Despite many efforts by many researchers, exactly how owls achieve silent flight is still an open question,’ says senior author Professor Hao Liu from the Graduate School of Engineering at Chiba University in Japan. ‘Understanding the precise role of TE fringes in their silent flight will enable us to apply them in developing practical low-noise fluid machinery.’”
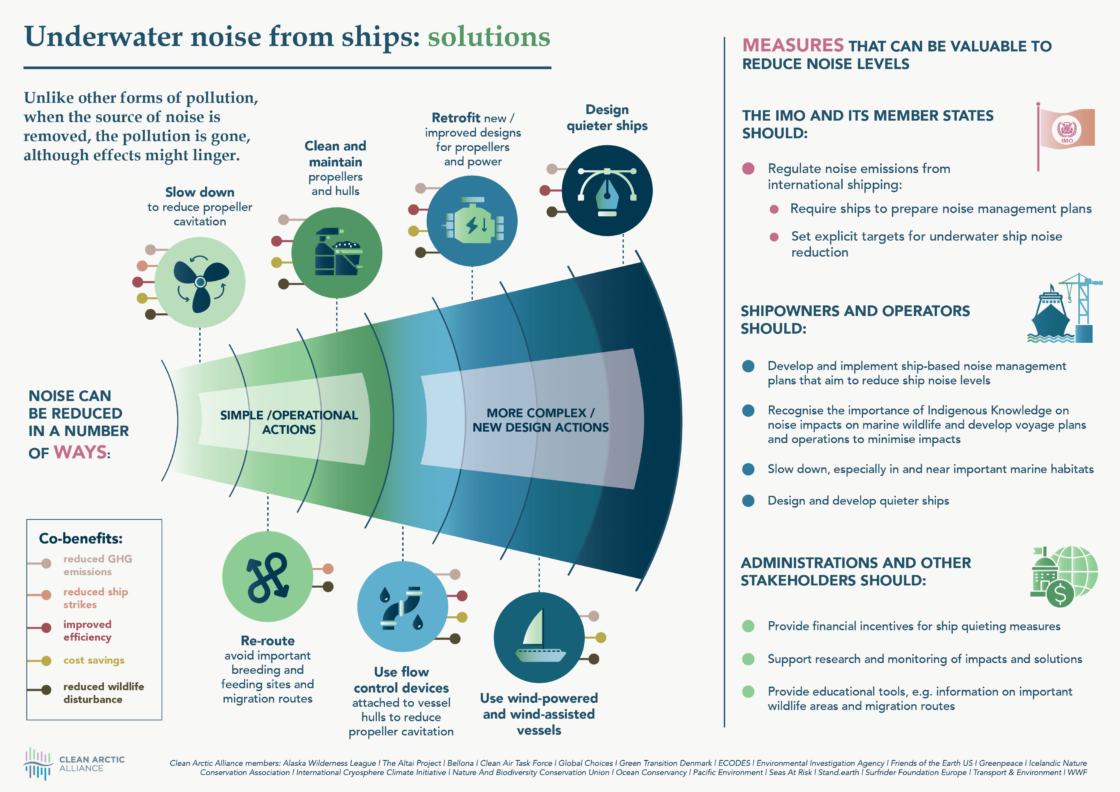
▰ QUICK NOTES: FM Blues: A radio station, WERA 96.7 in Arlington, Virginia, has been playing lofi beats on loop non-stop since the start of December 2023, due to delays in the station’s relocation. (Thanks, Mike Rhode!) ▰ Long Now: A “639-year organ performance” of a work by John Cage continues apace in Germany. (Thanks, Alan Bland!) ▰ Water Log: Sonar may — keyword: may — have discovered the remains of Amelia Earhart’s plane. ▰ In Sync: A musician and sound designer waxes rhapsodic over the moments when the two blend. ▰ Ah Om: A friend of one of the creators of the Buddha Machine shares some stories about their development. ▰ Ear Witness: Shazam can now identify what song you’re listening to while you have headphones on. ▰ Good Fences: A lovely blog entry, complete with ample photography and audio examples, by Sean Julian on making “vibration recordings,” in which he listens to fences. (Thanks, Grant Wilkinson!) ▰ Cold Truth: These date back to September of last year, when the Clean Arctic Alliance launched a campaign about underwater noise pollution:
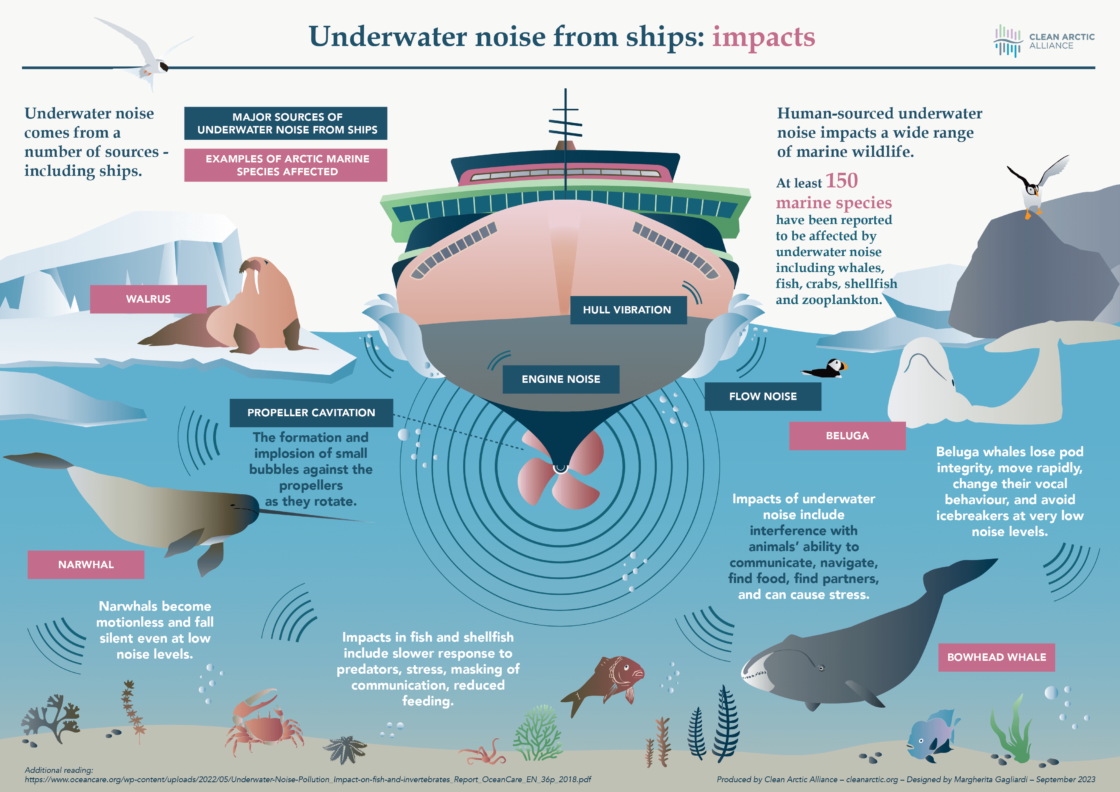
I only had room for one of these in the issue, but here’s a second Clean Arctic Alliance infographic: